Comment faire cohabiter intelligement données métier et données issues d’OSM pour votre métier ?
Exemple 1 : gestion des colonnes de collecte des déchets.
Durant toutes ces années de contribution à OpenStreetMap, j’avais en tête de concrétiser cette rencontre magique entre les données métiers issues de nos services et celles des contributeurs OpenStreetMap.
Mais au-delà de faire cette jointure une seule fois, l’objectif était de faire en sorte que ce lien se fasse automatiquement dès la modification de l’un de ces jeux de données réalisée et malgré le fait que ces mises à jour soient complètement indépendantes et désynchronisées. De plus, il fallait pouvoir s’appuyer sur une application concrète pour que cela apporte une vraie plus-value aux services.
Un des enjeux majeur pour un responsable SIG, c’est de rendre les services autonomes dans la mise à jour des données dont ils ont la gestion. A cela, il faut pouvoir garantir la qualité de cette donnée et, plus particulièrement, minimiser les risques d’erreurs lors de la saisie.
Un des moyens, simple mais efficace, est de mettre en place des listes de valeurs pour que l’utilisateur n’ait plus qu’à choisir la valeur plutôt que de la saisir manuellement. Cependant, ce système ne s’applique pas facilement à tous les types de données. Par exemple, avoir un très grand nombre d’adresses dans une liste de choix rendra la mise à jour insupportable pour les agents. Il faut alors privilégier les outils SIG qui permettent d’aller récupérer directement les informations dans les différentes tables à partir de requêtes spatiales.
Je vous propose aujourd’hui de voir comment automatiser le lien entre une donnée issue d’OpenStreetMap et des données métiers. Le prérequis à cet exercice est que vous ayez stocké les données provenant de ces 2 sources dans une base Postgresql.
Les logiciels utilisés pour cet exemple sont Vmap (Société Veremes) pour la partie WebSIG, FME (Safe) pour le traitement final et PGAdmin 4 pour les requêtes SQL. Si vous avez des outils similaires à ceux-là, vous ne devriez pas avoir trop de problème à adapter ce projet.
La base de données utilisée est, bien entendue, une base Postgresql. Les données utilisées sont celles des colonnes de collecte des déchets de la CCPRO, les adresses enregistrées sur OpenStreetMap et les données graphiques du cadastre DGFIP.
Le contexte est de faciliter le travail de saisie d’un agent dont la mission relève de la gestion des colonnes de collecte des déchets. L’agent doit faire le moins de manipulation et de saisie possible pour que ce travail soit rapide et pour limiter les erreurs de saisie. On doit privilégier les listes de choix et récupérer le plus d’information possible de manière automatique. Il faut également garder l’historique des modifications des objets pour savoir qui a fait quoi et quand, en cas de problème de saisie.
Démonstration du projet
L’action se déroule un lundi matin, alors qu’au dehors tout semble paisible et immobile. Un agent souhaite ajouter une nouvelle colonne sur le websig. Il peut le faire depuis son bureau ou sur le terrain avec une localisation GPS. Il saisit un minimum d’information et peut même ajouter une photo.
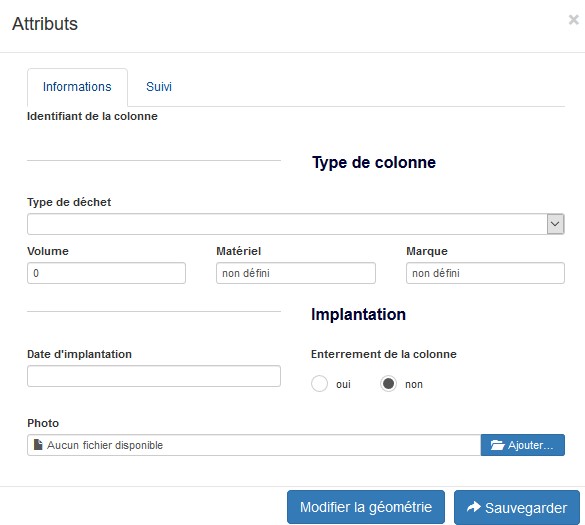

En option, il peut gérer la maintenance de la colonne avec des données pré remplies. Pour l’agent, le travail est déjà fini, il peut passer à autre chose. Une fois la colonne ajoutée, On peut déjà voir le taux de remplissage des bacs (1) sur la carte et une alerte (2) nous indique si le bac est rempli au moins aux ¾ de sa capacité.

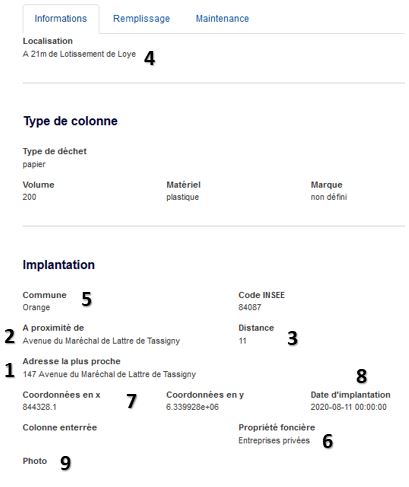
Si on retourne dans la fiche de la parcelle, on remarque plusieurs choses:
On vient de récupérer automatiquement l’adresse (1) et le tronçon de rue les plus proches (2) de la colonne (qui peuvent ne pas être les mêmes) avec la distance qui les sépare (3) et le point d’intérêt le plus proche (4). Toutes ces informations proviennent des données OpenStreetMap.
Dans le même temps, on récupère la commune où est implantée la colonne (5) et on a également la propriété foncière sur laquelle elle se trouve (6). Si la colonne se trouve dans la rue, l’attribut « Propriété foncière » indiquera la valeur « Espace public ». Sinon, on aura le type de propriétaire, ce qui nous permet de garder l’anonymat du propriétaire. On saura si la parcelle appartient à une administration, à une entreprise ou à un particulier.
Enfin, on récupère les coordonnées gps (7) en RGF93 (EPSG 2154) et la date de création (8) de l’objet dans la base de données. Si l’agent a pris une photo (9), elle apparait dans la fiche descriptive et l’attribut « Photo » prend la valeur « true », ce qui permet de faire une analyse cartographiques des colonnes pour indiquer celles d’entre-elles pour lesquelles nous avons une photo.
Un peu plus tard, l’agent retourne sur le terrain et remarque que la colonne est au ¾ pleine. Il va pouvoir modifier cette information et indiquer si la colonne a été vidée ou non.
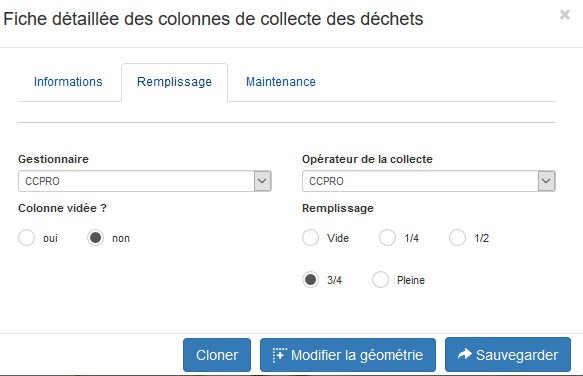
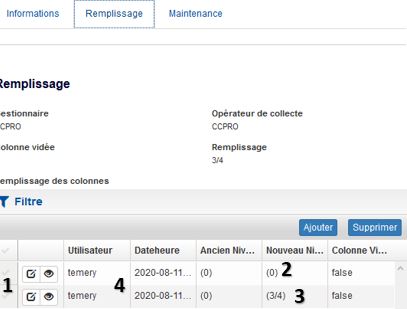
Dans l’onglet « Remplissage », on peut modifier le taux de remplissage de la colonne et on voit bien ensuite les 2 étapes apparaitre dans la fiche (1). La colonne était vide à la création de l’objet (2). Elle est désormais au ¾ pleine (3) et on sait qui a apporté la modification et quand (4).
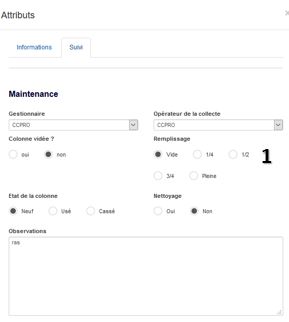
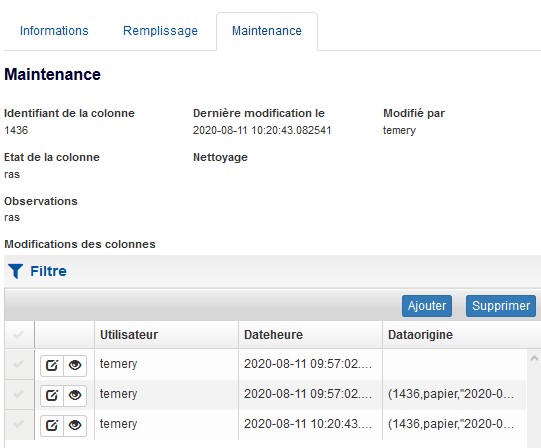
Dans l’onglet « Maintenance », on peut voir toutes les modifications qui ont été apportées à l’objet graphique.
La même chose se passe si l’agent va sur le terrain vérifier si la colonne est sale ou détériorée ou s’il faut l’enlever ou la changer de place. A chaque modification d’un objet de la base, une nouvelle ligne est créée, permettant ainsi de suivre l’historique des modifications.
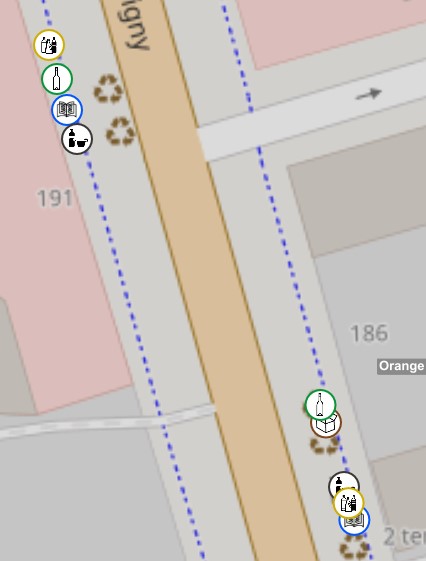
Les colonnes sont regroupées à certains endroits de la ville. Pour plus de lisibilité, il fallait qu’à un certain seuil de zoom, les colonnes fusionnent pour synthétiser les sites et avoir une information par site plutôt que par colonne.
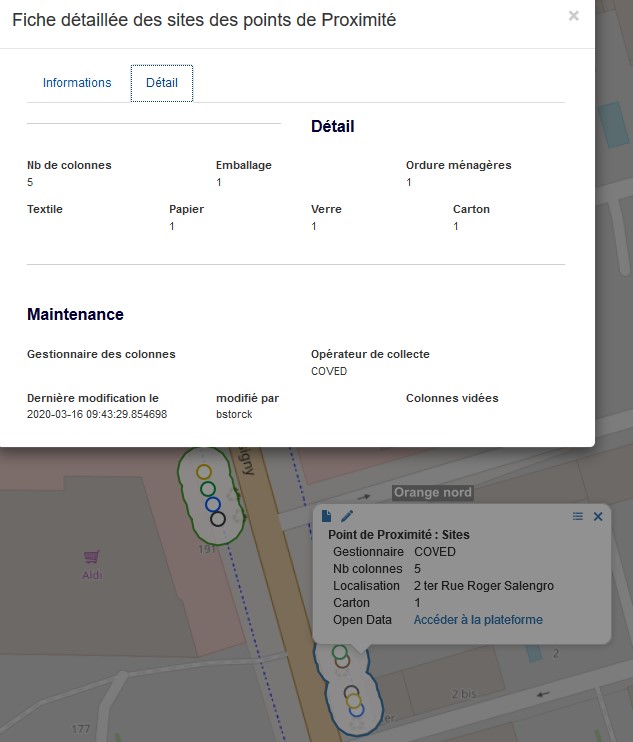
Lorsque qu’on sélectionne un site, nous avons une synthèse du nombre de colonnes par type de déchet et quelques infos communes aux colonnes de ce site.
Nous venons de voir le principe de fonctionnement du projet. Je vous propose maintenant d’aller plus loin dans la technique et de voir comment cela se passe dans la base de données.
Principes techniques
Pour effectuer toutes ces automatisations, nous allons utiliser 2 outils : Postgresql et FME. Ce projet étant toujours en phase d’évolution, l’objectif final est de pouvoir réaliser l’ensemble de ces opérations uniquement avec Postgresql.
La table des colonnes s’appelle, dans Postgresql, « env_colonnes ». Elle est associée à 3 déclencheurs (ou triggers) :
- trigger_horodatage ;
- trigger_maj_colonnes ;
- trigger_suivirempl_colonnes
FME intervient à la fin, dans la phase de création des sites à partir de « buffers » générés autour des colonnes.
trigger_horodatage
Le trigger_horodatage permet d’horodater les mises à jour des colonnes de collecte des déchets. Le paramétrage est le suivant :
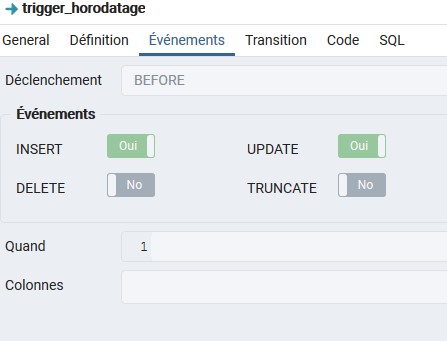
Il se déclenche donc avant la mise à jour, au moment de l’insertion d’un objet ou d’une mise à jour de la table.
En synthèse, le trigger va :
- ajouter la date et le nom de l’utilisateur qui a modifié l’objet ;
- ajouter le lien OpenData pour télécharger le jeu de données ;
- récupérer les coordonnées géographiques de la colonne en RGF93 (EPSG 2154) ;
- vérifier si une photo a été prise pour cet objet ;
- Récupérer le code et le nom de la commune via une requête spatiale sur la table DGFIP des communes ;
- Récupérer le type de propriété via une requête spatiale sur une table issue des données DGFIP anonymisées ;
- Récupérer le tronçon de voie OpenStreetMap le plus proche et la distance qui les sépare ;
- Récupérer l’adresse OpenStreetMap la plus proche et la distance qui les sépare ;
- Récupérer le point d’intérêt OpenStreetMap le plus proche et la distance qui les sépare.
Le code suivant est commenté. Vous pouvez donc voir ce que fait le code à chaque étape :
DECLARE
BEGIN
-- ajout de la date du jour et de l'utilisateur
NEW.date_valid := current_timestamp;
NEW.modified_by := session_user;
-- ajout du lien OpenData
NEW.lien_datasud := 'Accéder à la plateforme';
-- récupération des coordonnées géographiques de la colonne
NEW.coord_x := ST_X(NEW.geom);
NEW.coord_y := ST_Y(NEW.geom);
-- vérifie si une photo est présente
--SELECT INTO NEW.photo (case when photo_colonne = '' then 'false' else 'true' end) FROM s_environnement.env_colonnes;
CASE WHEN NEW.photo_colonne = '' THEN NEW.photo = 'false';
WHEN NEW.photo_colonne IS NULL THEN NEW.photo = 'false';
ELSE NEW.photo = 'true'; END CASE;
-- jointure spatiale pour récupérer l'id et le nom de la commune
SELECT INTO NEW.id_com id_com FROM s_cadastre.commune WHERE ST_WITHIN(NEW.geom,geom);
SELECT INTO NEW.commune initcap(texte) FROM s_cadastre.commune WHERE ST_WITHIN(NEW.geom,geom);
-- jointure spatiale pour récupérer le type de propriété de la parcelle
SELECT INTO NEW."public_privé"
(case when type_proprietaire like '%01_%' then 'Administration publique'
when type_proprietaire like '%02_%' then 'Administration publique'
when type_proprietaire like '%10_%' then 'Administration publique'
when type_proprietaire like '%30_%' then 'Administration publique'
when type_proprietaire like '%31_%' then 'HLM'
when type_proprietaire like '%50_%' then 'Entreprises privées'
when type_proprietaire like '%52_%' then 'Entreprises privées'
when type_proprietaire like '%53_%' then 'Entreprises privées'
when type_proprietaire like '%54_%' then 'Entreprises privées'
when type_proprietaire like '%55_%' then 'Entreprises privées'
else 'Privé' end)
FROM s_cadastre.ccpro_parcelles_proprio WHERE ST_WITHIN(NEW.geom,geom);
-- initialise la valeur 'public_privé' pour le cas où la colonne ne se trouve pas sur une parcelle
NEW."public_privé" := (case when NEW."public_privé" is not null then NEW."public_privé"
else 'Espace public' end);
-- récupération de la voie la plus proche
SELECT INTO NEW.voie_trouvee voie_trouvee FROM s_environnement.voie_proche WHERE NEW.id_serial = voie_proche.id_serial;
SELECT INTO NEW.distance_voie distance_voie FROM s_environnement.voie_proche WHERE NEW.id_serial = voie_proche.id_serial;
-- récupération de l'adresse la plus proche
SELECT INTO NEW.adresse_proche adresse_proche FROM s_environnement.adresse_proche WHERE NEW.id_serial = adresse_proche.id_serial;
SELECT INTO NEW.distance_adresse distance_adresse FROM s_environnement.adresse_proche WHERE NEW.id_serial = adresse_proche.id_serial;
-- récupération du POI le plus proche
SELECT INTO NEW.adresse_saisie ('A ' || distance_poi || 'm de ' ||nom_poi) FROM s_environnement. adresse_proche WHERE NEW.id_serial = poi_proche.id_serial;
RETURN NEW;
END;
La dernière partie du code concerne la proximité entre une colonne et la voie, l’adresse et le point d’intérêt les plus proche. Vous pouvez voir que nous avons fait une jointure entre la table des colonnes et les tables voie_proche, adresse_proche et adresse_proche.
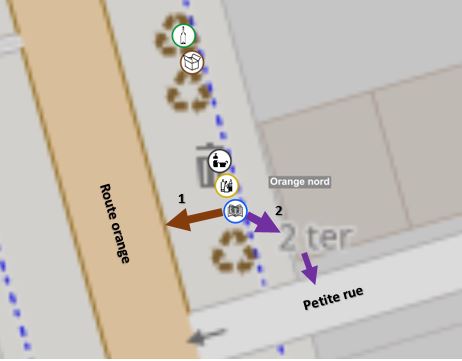
A la question « pourquoi récupérer à la fois le tronçon, l’adresse et le point d’intérêt les plus proches », la réponse est que dans certains cas particuliers, ils sont différents. Exemple ci-contre avec une colonne située le long de la Route orange. Cette route n’a pas d’adresse. Par contre, l’adresse la plus proche (2ter) est située sur la Petite rue. On a donc l’info que la colonne est accessible depuis la Route orange (1) et, comme elle peut être très longue, on indique qu’elle est proche de l’adresse 2ter qui se trouve sur la Petite rue (2). Idem pour les points d’intérêts dans le cas où l’adresse la plus proche est trop éloignée de la colonne.
Cette partie est réalisée à partir de plusieurs tables créées par un autre processus automatisé dans Postgresql et que nous allons voir maintenant. Il s’agit, en fait, de vues créées selon le modèle suivant (ici, les tronçons de voie) :
SELECT DISTINCT ON (t1.id_serial) t1.id_serial, t2.nom AS voie_trouvee, round(st_distance(t1.geom, t2.geom)::numeric, 0) AS distance_voie
FROM s_environnement.env_colonnes t1,
( SELECT linktable.nom, linktable.geom
FROM dblink('hostaddr=[adresse_hote] port=5432 dbname=[nom_base] user=[utilisateur] password=[mot_passe]'::text, 'SELECT nom, the_geom FROM public.theme_voirie'::text) linktable(nom text, geom geometry)) t2
WHERE st_dwithin(t1.geom, t2.geom, 300::double precision)
ORDER BY t1.id_serial, (st_distance(t1.geom, t2.geom));
Ici, on va récupérer l’identifiant de la colonne (id_serial), le nom de la voie de l’adresse ou du point d’intérêt le plus proche (voie_trouvee) et la distance qui les sépare (distance_voie). Comme il s’agit d’une table située dans une autre base de données, il a fallu utiliser dblink pour faire le lien. On récupère la voie la plus proche dans une limite de 300m autour de la colonne. Pour calculer la distancer entre 2 objets, c’est la requête : round(st_distance(t1.geom, t2.geom)::numeric, 0) : on fait un arrondi à l’entier près.
La table des points d’intérêt proches des colonnes est plus complexe car il utilise au préalable 2 autres vues :

Les tables poi_pnt_proche et poi_pol_proche sont construites selon le même modèle que précédemment. On a donc une table qui renseigne le point d’intérêt le plus proche et une table qui renseigne le polygone d’intérêt le plus proche. Comme on veut le POI le plus proche, que ce soit un point ou un polygone, on en ensuite la table poi_proche qui est construite en prenant l’objet le plus proche de chaque colonne de collecte. Voici le code :
SELECT COALESCE("proximité".id_serial_pnt, "proximité".id_serial_pol) AS id_serial,
LEAST("proximité".distance_pnt, "proximité".distance_pol) AS distance_poi,
CASE
WHEN "proximité".distance_pol IS NULL THEN "proximité".nom_pnt
WHEN "proximité".distance_pnt IS NULL THEN "proximité".nom_pol
WHEN "proximité".distance_pol <= "proximité".distance_pnt THEN "proximité".nom_pol
ELSE "proximité".nom_pnt
END AS nom_poi,
CASE
WHEN "proximité".distance_pol IS NULL THEN "proximité".tags_pnt
WHEN "proximité".distance_pnt IS NULL THEN "proximité".tags_pol
WHEN "proximité".distance_pol <= "proximité".distance_pnt THEN "proximité".nom_pol
ELSE "proximité".tags_pnt
END AS tags_poi,
CAS
WHEN "proximité".distance_pol IS NULL THEN 'point'::text
WHEN "proximité".distance_pnt IS NULL THEN 'polygone'::text
WHEN "proximité".distance_pol <= "proximité".distance_pnt THEN 'polygone'::text
ELSE 'point'::text
END AS type_poi
FROM ( SELECT pnt.id_serial AS id_serial_pnt,
pnt.nom AS nom_pnt,
pnt.tags AS tags_pnt,
pnt.distance_poi AS distance_pnt,
pol.id_serial AS id_serial_pol,
pol.nom AS nom_pol,
pol.tags AS tags_pol,
pol.distance_poi AS distance_pol
FROM s_environnement.poi_pnt_proche pnt
FULL JOIN s_environnement.poi_pol_proche pol ON pnt.id_serial = pol.id_serial) "proximité"
ORDER BY (COALESCE("proximité".id_serial_pnt, "proximité".id_serial_pol));
Pour chaque colonne, on va voir quel est le polygone (distance_pol) et le point (distance_pnt) le plus proche. On récupère la distance la plus courte (distance_poi). Avec un « CASE…WHEN…THEN…ELSE…END », on récupère le nom, les tags et le type de poi le plus proche de la colonne.
trigger_maj_colonnes
Le trigger_maj_colonnes permet de suivre la mise à jour des colonnes de collecte des déchets.
Il est paramétré de la manière suivante :
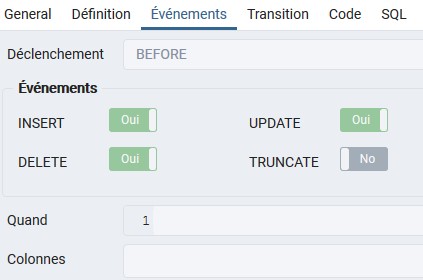
Il s’active avant la mise à jour, au moment de l’insertion ou de la suppression d’un objet ou d’une mise à jour de la table.
En synthèse, il va ajouter une ligne dans la table « suivi » à chaque fois qu’une modification de la table est faite. Les informations créées dans cette table diffèrent en fonction du type de modification.
Si une colonne de déchet est modifiée dans la table « env_colonnes », on ajoute dans la table « suivi » le schéma et le nom de la table, l’utilisateur, la date, l’action (UPDATE, DELETE ou INSERT), l’ancienne valeur, la nouvelle valeur, la requête effectuée et l’identifiant de l’objet.
Si une colonne de déchet est supprimée dans la table « env_colonnes », on ajoute dans la table « suivi » le schéma et le nom de la table, l’utilisateur, la date, l’action (UPDATE, DELETE ou INSERT), l’ancienne valeur, la requête effectuée et l’identifiant de l’objet.
Si une colonne de déchet est ajouté dans la table « env_colonnes », on ajoute dans la table « suivi » le schéma et le nom de la table, l’utilisateur, la date, l’action (UPDATE, DELETE ou INSERT, la nouvelle valeur, la requête effectuée et l’identifiant de l’objet.
>DECLARE
variable_ancienne_valeur TEXT;
variable_nouvelle_valeur TEXT;
identifiant INTEGER;
BEGIN
IF (TG_OP = 'UPDATE') THEN
variable_ancienne_valeur := ROW(OLD.*);
variable_nouvelle_valeur := ROW(NEW.*);
identifiant := OLD.id_serial;
INSERT INTO s_environnement.suivi (schema, nomtable, utilisateur, dateheure, action, dataorigine, datanouvelle, detailmaj, idobjet)
VALUES (TG_TABLE_SCHEMA::TEXT, TG_TABLE_NAME::TEXT, session_user, current_timestamp, substring(TG_OP,1,1), variable_ancienne_valeur, variable_nouvelle_valeur, current_query(), identifiant);
RETURN NEW;
ELSIF (TG_OP = 'DELETE') THEN
variable_ancienne_valeur := ROW(OLD.*);
identifiant := OLD.id_serial;
INSERT INTO s_environnement.suivi (schema, nomtable, utilisateur, dateheure, action, dataorigine, detailmaj, idobjet)
VALUES (TG_TABLE_SCHEMA::TEXT, TG_TABLE_NAME::TEXT, session_user, current_timestamp, substring(TG_OP,1,1), variable_ancienne_valeur, current_query(), identifiant);
RETURN OLD;
ELSIF (TG_OP = 'INSERT') THEN
variable_nouvelle_valeur := ROW(NEW.*);
identifiant := NEW.id_serial;
INSERT INTO s_environnement.suivi (schema, nomtable, utilisateur, dateheure, action, datanouvelle, detailmaj, idobjet)
VALUES (TG_TABLE_SCHEMA::TEXT, TG_TABLE_NAME::TEXT, session_user, current_timestamp, substring(TG_OP,1,1), variable_nouvelle_valeur, current_query(), identifiant);
RETURN NEW;
ELSE
RAISE WARNING '[s_environnement.fonction_maj_colonnes] - Other action occurred: %, at %', TG_OP,now();
RETURN NULL;
END IF;
END;
trigger_suivirempl_colonnes
Le trigger_suivirempl_colonnes permet le suivi du remplissage des colonnes de collecte de déchets.
Il est paramétré de la manière suivante :
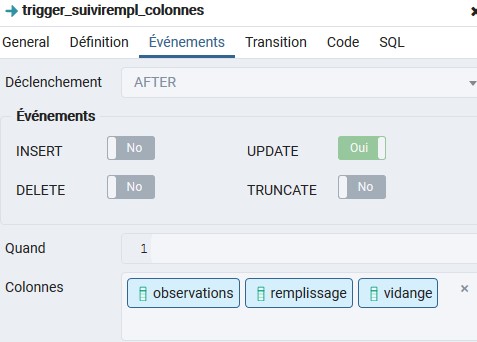
Il s’active avant la mise à jour et uniquement en cas de modification des attributs « observations », « remplissage » et « vidange » d’un objet déjà créé.
En synthèse, il va ajouter une ligne dans la table « remplissage_colonnes » à chaque fois qu’une modification de la table est faite. Á ce moment, le trigger ajoute dans cette table le schéma et le nom de la table, l’utilisateur, la date, l’action (UPDATE, DELETE ou INSERT), l’adresse, la commune, l’ancienne valeur, la nouvelle valeur, la requête effectuée et l’identifiant de l’objet.
DECLARE
variable_ancienne_valeur TEXT;
variable_nouvelle_valeur TEXT;
variable_ancienne_date TEXT;
variable_vidange TEXT;
variable_adresse TEXT;
variable_commune TEXT;
variable_observations TEXT;
identifiant INTEGER;
BEGIN
IF (TG_OP = 'UPDATE') THEN
variable_ancienne_valeur := ROW(OLD.remplissage);
variable_nouvelle_valeur := ROW(NEW.remplissage);
variable_ancienne_date := OLD.date_valid;
variable_vidange := NEW.vidange;
variable_adresse := NEW.adresse_proche;
variable_commune := NEW.commune;
variable_observations := NEW.observations;
identifiant := OLD.id_serial;
INSERT INTO s_environnement.remplissage_colonnes (schema, nomtable, utilisateur, dateheure, action, adresse, commune, ancien_niveau, nouveau_niveau, observations, detailmaj, idobjet, dernier_releve, colonne_videe)
VALUES (TG_TABLE_SCHEMA::TEXT, TG_TABLE_NAME::TEXT, session_user, current_timestamp, substring(TG_OP,1,1), variable_adresse, variable_commune, variable_ancienne_valeur, variable_nouvelle_valeur, variable_observations, current_query(), identifiant, variable_ancienne_date, variable_vidange);
--NEW.date_valid := current_timestamp;
--NEW.modified_by := session_user;
NEW.vidange := FALSE;
RETURN NEW;
ELSE
RAISE WARNING '[s_environnement.fonction_remplissage_colonnes] - Other action occurred: %, at %', TG_OP,now();
RETURN NULL;
END IF;
END;
Nous venons donc de voir les différents triggers qui se lancent directement dans la base de données Postgresql à chaque modification apportée par un agent dans la couche de données contenant les colonnes de collecte des déchets.
Il reste un dernier processus qui permet de créer une zone tampon autour des colonnes de collectes afin de regrouper les informations par site de collecte.
Création des sites des colonnes
Ce processus est réalisé à partir d’un projet FME qui est exécuté au moyen d’une tâche planifiée 2 fois par jour. Ce projet exécute 2 actions :
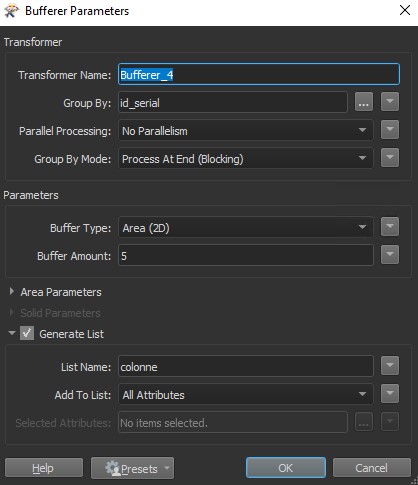
- Création d’une zone tampon de 5m autour des colonnes pour créer les sites de collecte ;
- Création de 3 zones tampons de 50, 100 et 200m autour des colonnes afin de générer des statistiques de proximité par rapport aux habitants.
Création des sites de collecte
Cette partie est organisée de la manière suivante :
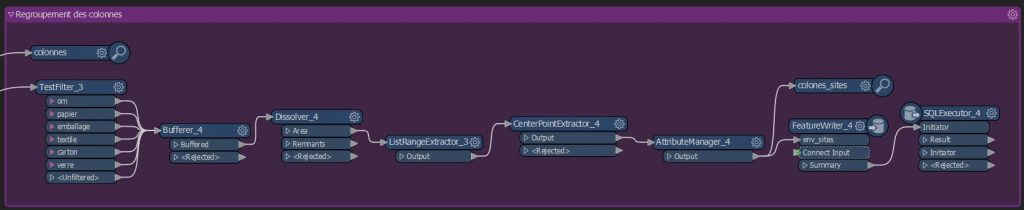
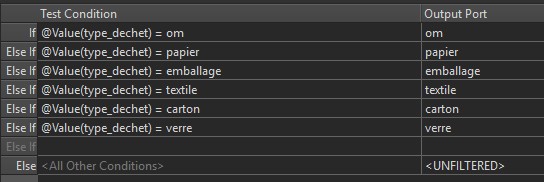
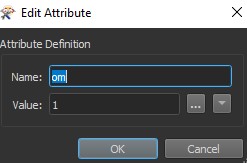
On fait un test (TestFilter_3) sur le type de déchet et, en fonction de la valeur de cet attribut, on va créer un nouvel attribut portant le nom du type de déchet (om, papier, emballage,…) et auquel on attribue la valeur « 1 ».
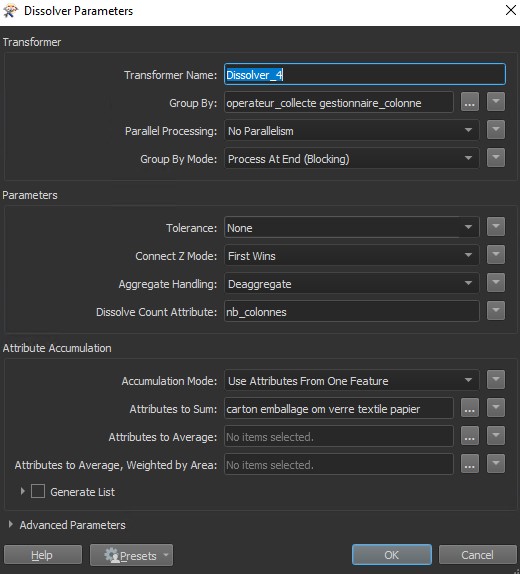
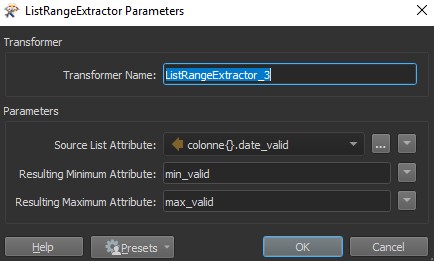
On va ensuite créer le buffer de 5m autour des colonnes et créant une liste pour conserver les valeurs des attributs de chaque colonne, fusionner ceux qui sont superposés et récupérer dans un attribut les valeurs minimum et maximum de l’attribut « date_valid ». De cette façon, on pourra savoir pour chaque site quelle était la date la plus récente de la dernière visite d’un agent. On récupère enfin le centroïde de la zone tampon et on enregistre le résultat dans Postgresql.
Création des zones d’analyse

Dans cette dernière partie, on reprend l’ensemble des traitements vus précédemment, à l’exception du filtre et de l’extraction des valeurs min et max de la date. On exécute cette partie pour chacun des 3 buffers : 50m, 100m et 200m.
Limites et évolutions du projet
L’avantage du projet dans son ensemble provient du côté dynamique du traitement : à chaque modification d’un agent, la base de données se met à jour dans la foulée et l’ensemble des services peuvent voir les changements effectués.
Pour autant, il reste deux choses à améliorer. La fin du processus utilise encore une tâche planifiée ce qui fait que la modification des sites de collecte ne se fait pas au même moment que le reste du projet. En effet, je rencontre encore des difficultés pour traduire en sql cette partie du projet mais cela fait partie de son évolution à venir.
Vous pouvez également voir qu’il a été mis en place un processus de suivi des modifications. On peut donc voir qui a modifier quel objet et quand. L’étape suivante devra permettre de revenir à une version antérieure en cas de constat d’une erreur de saisie.
Dans un prochain article, nous verrons un autre projet similaire qui concerne les activités économiques. C’est un sujet un peu plus complexe car plusieurs sources de données entrent en jeu.
Pour toute question, vous pouvez me contacter par mail à t.emery@ccpro.fr